How Companies and Academics Are Innovating the Use of Language Models for Research and Development
In a recent blog post (“Large Language Models like ChatGPT Begin to Permeate Bioinformatics”) we delved into the integration of ChatGPT-like AI models into bioinformatics pipelines, unveiling new possibilities for text mining, ontology, and other applications in computational biology. In this new post we embark on a broader exploration about how language models are becoming instrumental across diverse domains of research and development in biology by the private and public sectors.
It’s no wonder, as we’ve discussed in recent articles of our blog, that AI has become a cornerstone in various fields of science. In biology, for example, it is boosting fundamental discoveries (think of AlphaFold as the epitome) and product development (think of protein design) at all-time highs. But one special breakthrough in AI in principle unrelated to scientific applications, Large Language Models (LLMs) like ChatGPT, has also recently sparked remarkable strides in shaping the future of fundamental and applied research. And we are not talking about the obvious use of LLMs to assist scientific text mining, summarization, automated data retrieval and question answering from long texts, or other language tasks, not even about how they boost productivity in a myriad of forms -despite we acknowledge they are all truly helpful per se- but rather about the possibility of having LLMs do actual science. Not like AI models devised and trained specifically to target specific problems, but rather by building on their “understanding” of language and data.
Importantly, “language” in LLMs does not simply mean human language but also scripting and programming languages as well as the languages that define formats, data structures, etc. Indeed, LLMs are extremely powerful at converting back and forth between source code and natural human language, being capable of interpreting code to explain how it works, detect bugs and correct them, or the other way around, creating code in response to a question or request. Both ways from code to natural language and back are extremely powerful sources of innovation regarding how we edit and create code, how we teach and learn programming, and, as explored more recently and focus of this article, in automating data analysis.
Despite this power of LLMs has been known already from the times when early LLMs were released, their robust application to data analysis is more recent. A bunch of LLM-based solutions to data analysis have recently emerged along two main branches: those specialized to handle specific kinds of data, and those meant to treat data of generic form.
LLM-based systems for general data analysis
Among generalized LLM-based systems for data analysis, probably the most advanced solution is OpenAI’s own proprietary system, closed in a paid form and powered directly by GPT-4. Up next is RTutor.ai, more open than OpenAI’s solution, accessible without registration and based on a more transparent system that couples GPT-4’s capabilities on human language with its capabilities for writing R code, used as a scripting language. Staying general in the kind of data it accepts, RTutor.ai simplifies data analysis by providing a natural language interface for users to interact with their data. Users provide a dataset and then ask questions or give commands in plain English; and RTutor.ai translates the questions/commands into R code and execute it, all within a web-based platform. RTutor.ai can generate HTML reports, R plots and R Markdown files based on the user’s inputs and outputs.
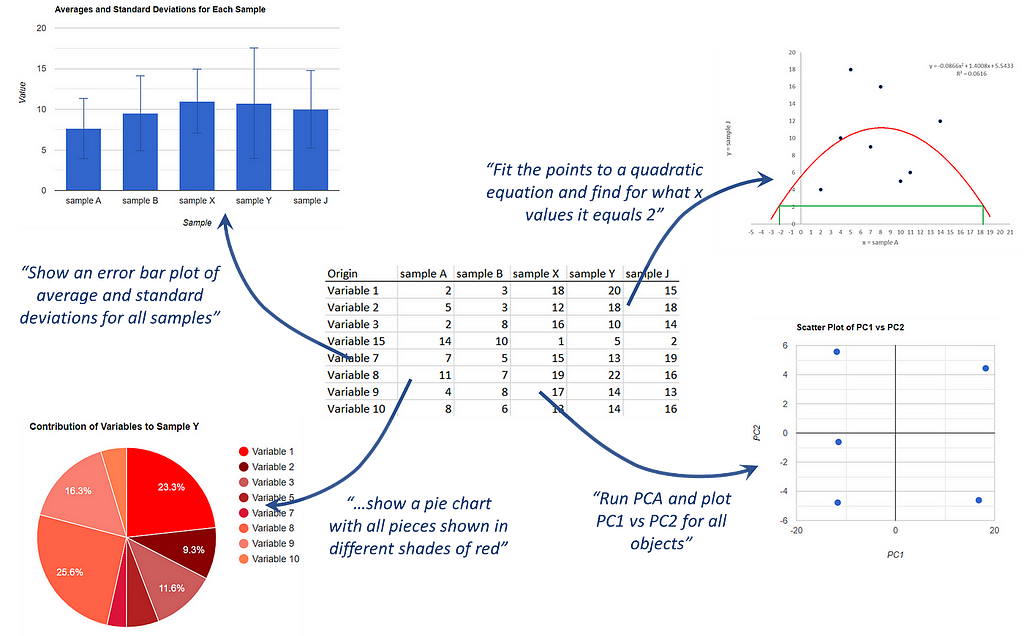
Featured in the lead figure of this article, StatBot (here) is a prototype system for non-specialized data analysis similar to RTutor.ai but specialized in JavaScript. Using either GPT-3.5-turbo or GPT-4, StatBot converts a user’s question or request into JavaScript code that runs in the web page and exploits libraries for advanced math and data plotting, displaying the results in a very graphical way that combines HTML formatting and the power of Google Charts’ interactive graphics.
LLM-based systems for field-specific data analysis
Staying general gives flexibility, but specialization allows for much more complex analyses. That’s why we at Nexco, as well as other companies and academics alike, are studying the power of LLMs to push the boundaries of innovation across diverse domains, and are already starting to develop new software based on that research.
LLMs and molecular structure
Among some surprising findings, OpenAI’s GPT models were found to perform rudimentary structural biology modeling. A preprint shows how ChatGPT can accurately model the 3D structures of standard amino acids without much prompting, and even of α-helical polypeptide chains when coupled to a Wolfram plugin for advanced mathematical computation that help model the geometrical features of the structure. Despite occasional errors and limitations in molecular complexity, the potential is there and could be enhanced with proper prompting and by coupling the LLM to small molecule libraries and other sources of structural information. Thus, despite the long shot, LLMs could in the future aid researchers in understanding structure-function relationships and perhaps even in molecule design.
This article details how GPT-4 can accurately dissect SMILES strings (string-based representations of small molecules very convenient for use in cheminformatics) into subparts that are relevant to the different properties of the molecule as well as for steps of synthesis. Moreover, GPT-4 performs in some cases reasonably well in discerning, classifying and prioritizing compounds depending on properties such as Lipinski’s rule of five, a rule that helps to approximately evaluate drug-likeness. More broadly, the article reimagines how drug discovery (and synthesis, and functional testing, etc.) could be revolutionized by LLMs, beyond the several applications of specialized AI systems.
With a similar spirit, this perspective article puts forward a central role for LLMs in the future, in planning and executing drug screening, design, synthesis, and experimental testing. LLMs can also serve as versatile interpreters, translating complex chemical data, predictions, and experimental outcomes into accessible natural language. In a near future, chemists may find themselves engaging in dynamic conversations with these models, obtaining insights, suggestions, and even generating experimental protocols through interactive dialogue. LLMs equipped with an understanding of chemistry and vast datasets will be able to assist in formulating experimental plans, recommending optimal conditions, and even proposing alternative approaches based on their knowledge of chemical reactions, properties, and synthesis pathways.
LLMs trained specifically and exclusively on molecular (as opposed to human language) data such as protein sequences (like Meta’s ESMFold, to predict protein structures) or small molecule SMILES (for example to predict reagents from products) are themselves already revolutionizing their fields of application. In a future where these LLMs are integrated with ChatGPT-like LLMs that also handle human language, systems could emerge in which users can ask for molecules with specific functional groups, sizes, properties, synthesis pathways, etc. Already in this direction, this preprint presents a system that can analyze a molecule’s structure and derive a natural-language explanation of its properties and functions.
LLMs to Assist Biological Discoveries
New computational methods, many from academia but notably several from companies, are applying LLMs to data analysis on specific domains creating new, revolutionary ways to advance biology.
RTutor.ai, presented in the first section, includes a preset example dealing with RNA-seq data on which a user can ask simple questions in ways far easier than the alternative of loading the data into a program and then clicking lists of commands and actions or writing scripts. Likewise, companies including Nexco are developing tools specifically devised to target this kind of data analysis tasks. This specialization allows the inclusion of quite complex functions that a general-purpose system might overlook, making the tool very powerful.
In drug discovery, we saw above from a more chemical/structural viewpoint how LLMs are being explored us a tool for more seamless human interaction with molecular data, based on natural language. More into the hands-on advance in discovery, this report explains how pharma companies are already today using LLMs to directly interact with their target discovery platforms, to augment relationships and integrate data from knowledge graphs, to simplify data search and retrieval, to look for associations between genes and specific diseases by applying the LLM to annotations, and more.
LLMs in medicine
In medicine, chatbot technology has been used for quite some time to improve patient care by providing 24/7 medical advice and assistance. Like in most chatbot applications before the LLM era, these used to be rule-based and inflexible. Now, LLM-based chatbots can take the user experience to a new level, by allowing flexible interaction, good conversation tracking, a variety of languages, etc. Pursuing the same advantages, some pharma training and consultation websites like this one offer LLM-based chatbots coupled to their content, that greatly facilitate information retrieval. All this, however, comes with the potential problems of hallucination, misinformation and biases, today the subject of active research by LLM developers and academics.
From Google, an LLM called Med-PaLM 2 is a research model carefully developed to answer medical questions accurately and helpfully, using the medical domain as a guide. It is one of the foundation models for MedLM, a family of fine-tuned language models for the healthcare industry. It reached human expert level on medical questions from the US Medical Licensing Examination entity. It builds on Google’s previous general LLM, called PaLM, from which it was largely improved to avoid problems typical of LLMs that would be dangerous for a chatbot with such an application. Namely, hallucination that could lead to incorrect information, discriminatory comments, and related issues. Even with such great deal of care practiced, Med-PaLM 2 is currently available only to a select group of customers for testing and feedback, with the goal of assessing the model’s ability to accurately and safely sift through and summarize vast stores of medical information and output useful, sensitive, correct answers.
More globally on applications to medicine, this comprehensive review highlights the architecture, application, and current role of ChatGPT and older-style chatbots in assisting medical diagnosis, treatment, etc. While acknowledging the immense promise of large language models like ChatGPT in healthcare, the article also emphasizes the need for further research to address limitations and challenges.
The Future of LLMs for Bioinformatics at Nexco
At Nexco we are excited about the possibilities of LLMs in streamlining our users’ curiosity, expertise and intentions when working with large datasets, so that they can focus on the scientific questions and answers without having to worry about the how-to.
Counting with experts in AI including experts in LLMs, we are right now developing LLM-based tools that will allow users to run their own custom analyses at high depth and complexity, without having to write a single line of code.
Stay tuned for our website’s assistant chatbot coming soon to guide you through our website and to answer the questions you have about us and our services. And then stay tuned for exciting developments including our ONex tool for genomics data analysis and future evolutions using natural language processing for human-computer interaction along our data analysis pipelines.
Additional references (besides those given throughout the text)
https://www.nature.com/articles/s41587-023-01788-7
https://nexco.ch/blog/Large-Language-Models-like-ChatGPT-Begin-to-Permeate-Bioinformatics
Related Posts

Our location
Nexco Analytics Bâtiment Alanine Route de la Corniche 5B 1066 Epalinges, Switzerland
Give us a call
+41 76 509 73 73
Leave us a message
contact@nexco.chDo not hesitate to contact us
We will answer you shortly with the optimal solution to answer your needs
© 2024 Nexco Analytics. All Rights Reserved.